为省赛整理的常用算法模板,动态规划部分
01背包

1 | int dp[MAX_W + 1]; |
多重背包
N 种物品重量和价值和个数分别为 wi, vi, ni,从这些物品中挑出总重量不超过 W 的物品,求所有挑选方案中价值总和最大。
dp[i + 1][j] = max(dp[i][j − k × w[i]] + k × v[i]|0 ≤ k ≤ ni&&k × w[i] ≤ j)
相当于 ni 个 01 背包。
1 | int dp[MAX_W + 1]; |
经过二进制优化后1
2
3
4
5
6
7
8
9
10
11
12
13
14
int dp[MAX_W + 1];
memset(dp, 0, sizeof(dp));
for(int i=0; i<N; ++i) {
int num = n[i];
for(int j=1; j<=num; j<<=1) {
for(int k=W; k>=j*w[i]; --k)
dp[k] = max(dp[k], dp[k-j*w[i]]+j*v[i]);
num-=j;
}
if(num)
for(int k=W; k>=num*w[i]; --k)
dp[k] = max(dp[k], dp[k-num*w[i]]+num*v[i]);
}
完全背包
N 种物品重量和价值分别为 w i , v i ,每种物品无限个,从这些物品中挑出总重量不超过 W 的物品,求所有挑选方案中价值总和最大。
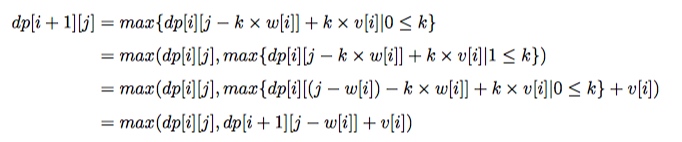
1 |
|
最长公共子序列
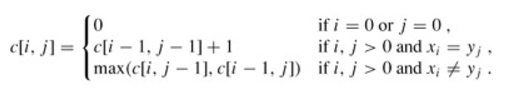
二维简单版:1
2
3
4
5
6
7
8
9
10
11
12
13int dp[maxn][maxn];
int LCS(string a,string b) {
memset(dp, 0, sizeof(dp));
for(int i=0; i<a.length(); ++i) // a
for(int j=0; j<b.length(); ++j) { // b
if(a[i] == b[j])
dp[i+1][j+1] = dp[i][j] + 1;
else
dp[i+1][j+1] = max(dp[i][j+1], dp[i+1][j]);
}
return dp[a.length()][b.length()];
}
最长上升子序列
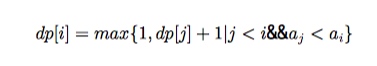
1 | int a[maxn], dp[maxn]; // a为序列, dp[i]为以a[i]为结尾的最长上升子序列长度 |
优化后,O(nlog(n)) 算法1
2
3
4
5
6
7
8
9
10
11int a[maxn], dp[maxn]; // a为序列, dp[i]为以a[i]为结尾的最长上升子序列长度
int LIS(int n)
{
memset(dp,0x3f,sizeof(dp));
for(int i=0;i<n;i++)
{
*lower_bound(dp,dp+i,a[i])=a[i];
}
return lower_bound(dp,dp+n,INF)-dp;
}
其中:
upper_bound,表示使用二分查找返回排序好的数组中值>k的最小的那个元素的指针
lower_bound,表示使用二分查找返回排序好的数组中值>=k的第一个元素的指针
多重部分和
问题描述:有 n 种大小不同的数字 ai,每种 mi 个,判断是否可以从这些数字中选出若干个使他们的和恰好为 K
设 dp[i+1][j] 为前 i 种数加和为 j 时第 i 种数最多能剩余多少个。(不能得到为-1)
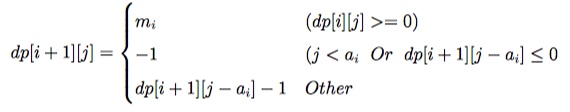
1 | int a[maxn],m[maxn],dp[maxm]; //a表示数,m表示数的个数,dp范围是所有数的和的范围 |
多重集的组合数
问题描述:有 n 种物品,第 i 种有 ai 个。不同种类的物品可以相互区分但相同种类的物品无法区分。从这些物品中取出 m 个的话,有多少种取法。结果取 Mod。
设 dp[i + 1][j] 为从前 i 个物品取出 j 个的组合数
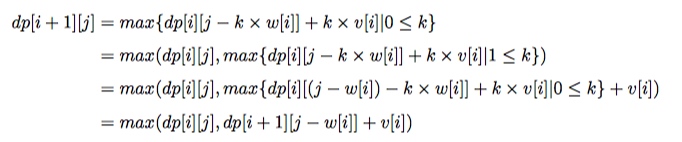
1 | int a[maxn],dp[maxn][maxm]; //dp[i+1][j] 表示从i种物品中取出j个的组合数 |
划分数问题
有n个无区别的物体,将他们划分成m组,问有多少种划分方法:
定义dp[i][j]为i个物体进行j组划分的方法数,则有:
dp[i][j]=dp[i-1][j]+dp[i][j-1]
数位DP模板
一般是求小于等于数字N的某些特征数字个数,或者是区间[L,R]的之间的某些特征数字个数,后者一般可以转换成求差的方式来做。
数字处理函数:1
2
3
4
5
6
7
8
9int f(int num){
int ans;
int pos = 0;
while(num){
digit[++pos]=num%10;
num=num/10;
}
return dfs( pos, s , true );
}
其中:
digit为处理串的每个数位的数值。
s为初始的状态。
如果有其他限定条件,dfs中可以增加参数。
DFS函数:1
2
3
4
5
6
7
8
9
10
11
12
13ll dfs(int l,int s,bool jud) //l表示当前处理的位置,s表示状态,jud表示是否是上界的前缀
{
if(l==0) return 1; //l是0还是-1取决于怎样存储数
if(!jud && dp[l][s]!=-1) return dp[l][s]; //排除上界的前缀情况
int len=jud?digit[l]:9;
ll ans=0;
for(int i=0;i<=len;i++)
{
dosomething //表示其他处理条件,比如剔除不符合的部分数 if(i==9 && fo)continue;
ans+=dfs(l-1,new_s(s,d),jud && i==len);
}
return jud ? ans : dp[l][s] = ans; //排除上界前缀和的情况
}
其中:
dp为记忆化数组;
l为当前处理串的第l位(权重表示法,也即后面剩下l+1位待填数);
s为之前数字的状态(如果要求后面的数满足什么状态,也可以再记一个目标状态t之类,for的时候枚举下t);
jud表示之前的数是否是上界的前缀(即后面的数能否任意填)。
for循环枚举数字时,要注意是否能枚举0,以及0对于状态的影响,有的题目前导0和中间的0是等价的,但有的不是,对于后者可以在dfs时再加一个状态变量z,表示前面是否全部是前导0,也可以看是否是首位,然后外面统计时候枚举一下位数。It depends.
于是关键就在怎么设计状态。当然做多了之后状态一眼就可以瞄出来。
前导零的判断:1
2
3
4int dfs(bool zero)
......
ans+=dfs(zero&&i==0)//不区分前导零与零
ans+=dfs(zero&&i==0&&l>1)//区分前导零与零

