《深入理解计算机系统》第5章笔记
编写高效程序可以考虑两个方面:选择好的算法和数据结构;编写编译器能够有效优化以转换为高效可执行代码的源码。
程序员通常需要在实现和维护程序的简单性与他的运行速度之间做出权衡折中。
程序优化的第一步就是消除不必要的内容,让代码尽可能有效地执行它期望的工作。这包括消除不必要的函数调用、条件测试和存储器引用。这些优化不依赖于目标机器的任何具体属性。
研究程序的汇编代码表示,是理解编译器,以及产生的代码如何运行的最有效的手段之一。仔细研究内循环的代码是一个很好的开端。
优化编译器的能力和局限性
编译器优化程序的能力受到几个因素的制约:
- 要求决不能改变正确程序的行为
- 对程序的行为、使用的环境有所了解
- 需要很快地完成编译工作
阻碍优化的几个因素:
- 存储器别名的使用,编译器必须假设不同的指针可能会指向存储器中的同一个位置
- 函数调用,函数可能会有副作用(改变全局程序状态的一部分)
表示程序性能
我们引入度量标准每元素的周期数(Cycles Per Element, CPE)作为一种表示性能并指导我们改进代码的方法。处理器活动的顺序是由时钟控制的,时钟提供了某个频率的规律信号,通常用千兆赫兹(GHz),即十亿周期每秒来表示。CPE 越小越好。
消除循环的低效率
优化前

优化后

以上的代码移动(code motion)是一种优化。这类优化包括识别要执行多次(例如在循环里)但是计算结果不会改变的计算。因而可以将计算移动到代码前面不会被多次求值的部分。
编程时一个常见的问题就是一个看上去无足轻重的代码片段有隐藏的渐进低效率(asymptotic inefficiency)
减少过程调用
过程调用会代码相当大的开销,而且妨碍大多数形式的程序优化。我们可以直接访问数组,而不是利用函数调用并加上边界检查:

对于性能至关重要的程序来说,为了速度,可能需要损害一些对象的模块性和抽象性
消除不必要的存储器引用
累加过程中其实没有必要每次都把结果写入到 dest 中,可以使用一个临时变量,消除不必要的存储器引用:

理解现代处理器
不依赖目标机器的优化,只能简单通过降低过程调用开销、以及消除一些重大的“妨碍优化因素”来实现。
要想获得充分提高的性能,需要仔细地分析程序,同时代码的生成也要针对目标处理器进行调整。在实际的处理器中,是同时对多条指令求值,这个现象称为指令级并行。现代微处理器取得的了不起的功绩之一是:它们采用复杂而奇异的微处理器结构,其中,多条指令可以并行地执行,同时又呈现一种简单地顺序执行指令的表象。
两种下界描述了程序的最大性能。当一系列操作必须按照严格顺序执行时,就会遇到延迟界限(latency bound),因为在下一条指令开始之前,这条指令必须结束。当代码中的数据相关限制了处理器利用指令级并行的能力时,延迟界限能够限定程序性能。吞吐量界限(throughput bound)刻画了处理器功能单元的原始计算能力。这个界限是程序性能的终极限制。
整数操作
Nehalem 微体系结构是 20 世纪 90 年代以来,许多制造商生产的典型的高端处理器。在工业界称为超标量(superscalar),意思是可以在每个时钟周期执行多个操作,而且是乱序的(out-of-order),意思就是指令执行的顺序不一定要与它们在机器级程序中的顺序一致。整个设计有两个主要部分:指令控制单元(Instruction Control Unit, ICU)和执行单元(Execution Unit, EU)。前者负责从存储器中读出指令序列,并根据这些指令序列生成一组针对程序数据的基本操作;而后执行这些操作。
ICU 从指令高速缓存(instruction cache)中读取指令。指令高速缓存是一个特殊的高速缓存存储器,它包含最近访问的指令。通常,ICU 会在当前正在的指令很早之前取指,这样它才有足够的时间对指令译码,并把操作发送到 EU。不过,一个问题是党程序遇到分支时,程序有两个可能的前进方向。一种可能会选择分支,控制被传递到分支目标。另一种可能是,不选择分支,控制被传递到指令序列的下一条指令。现代处理器采用了一种称为分支预测(branch prediction)的技术,处理区会猜测是否会选择分支,同时还预测分支的目标地址。使用投机执行(speculative execution)的技术,处理器会开始取出位于它预测的分支会跳到的地方的指令,并对指令译码,甚至在它确定分支预测是否正确之前就开始执行这些操作。如果过后确定分支预测错误,会将状态重新设置到分支点的状态,并开始取出和执行另一个方向上的指令。
功能单元的性能
每个运算都是由两个周期计数值来刻画的:一个是延迟(latency),它表示完成运算所需要的总时间;另一个是发射时间(issue time),它表示两个连续的同类型运算之间需要的最小时钟周期数。随着字长的增加,对于更复杂的数据类型,对于更复杂的运算,延迟也会增加。
处理器操作的抽象模型
我们会使用程序的数据流(data-flow)表示,作为分析在现代处理器上执行的机器级程序性能的一个工具,这是一种图形化的表示方法,展现了不同操作之间的数据相关是如何限制它们的执行顺序的。这种限制形成了图中的关键路径(critical path),这是执行一组机器指令所需时钟周期数的一个下界。
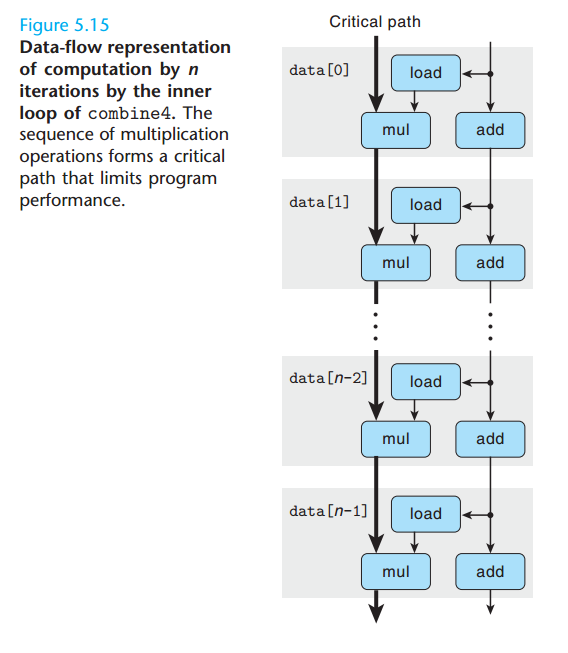
循环展开(loop unrolling)
循环展开是一种程序变换,通过增加每次迭代计算的元素的数量,减少循环的迭代次数。其思想是在一次迭代中访问数组并做乘法,这样得到的程序需要更少的迭代,从而降低循环的开销。
循环展开能够从两个方面改善程序的性能。首先,它减少了不直接有助于程序结果的操作的数量,例如循环索引计算和条件分支。其次,它提供了一些方法,可以进一步变化代码,减少整个计算中关键路径上的操作数量。
提高并行性
循环分割(loop splitting)
对于一个可结合可交换的合并操作来说,比如说整数的乘法和加法,我们可以通过将一组数据合并分割成两个或者更多部分,并在最后合并结果来提高性能
寄存器溢出(register spilling)
循环并行性的好处就是受描述计算的汇编代码的能力限制,如果我们有并行度p超过了可用的寄存器数量,这种情况性能就会急剧下降。
作为一条通用原则,无论何时当一个编译了的程序显示出来在某个频繁使用的内循环中有寄存器溢出的迹象时,都会偏向于重写代码,使之需要较少的临时值。
确定和消除性能瓶颈
Amdahl定律
当我们加快系统一部分的速度时,对系统整体性能的影响依赖于这个部分有多重要和速度提高了多少。
主要观点:想要大幅度提高整个系统的速度,我们必须提高系统很大一部分的速度。
小结
没有任何编译器能用一个好的算法或数据结构代替低效率的算法或数据结构,因此程序设计时的这些方面仍然应该是程序员主要关心的。

