使用Redis实现分布式爬虫
主要使用Scrapy、Redis、MongoDB实现,Scrapy作为异步爬虫框架、Redis实现分布式以及Cookies池的存储,MongoDB实现底层数据存储
分布式示意图
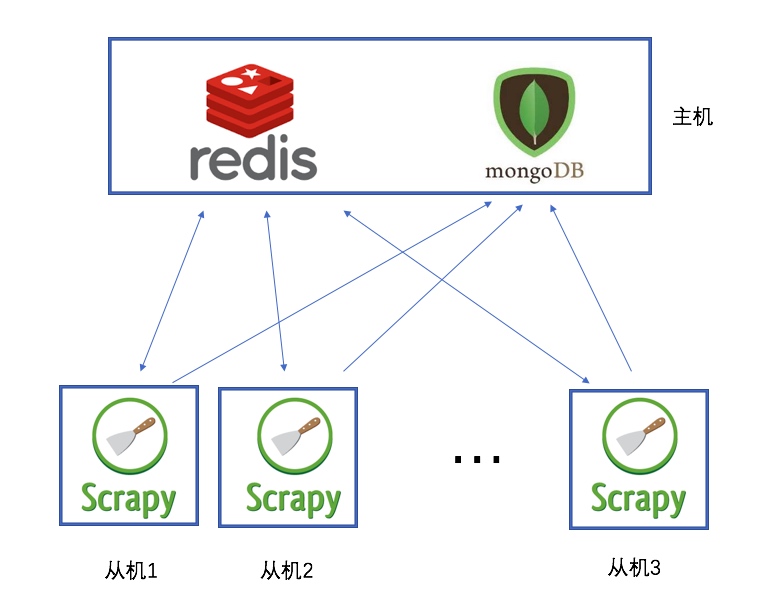
主机中安装Redis和MongoDB
Redis中存储:
- 所有Scrapy爬虫的待爬取队列
- 去重用的已发出Request指纹
MongoDB负责最终数据的存储
可创建多个Scrapy从机进行爬取,实现分布式。
Features
- 共享爬取队列实现分布式
- 生成Request的指纹实现分布式的去重
- 随机指定User-Agent
- 通过Redis实现Cookies池并进行更新
分布式实现
请求队列
各个分布式爬虫共同维护一个Request请求队列,使用的是Redis的list。队列可以实现FIFO,LIFO或者优先级队列。
爬取的时候一开始使用的是优先级队列,但是后来因为不好设置优先级,导致最后都是User的item,导致Rep的饥饿现象,所以到后面换成FIFO队列。
1 | class FifoQueue(Base): |
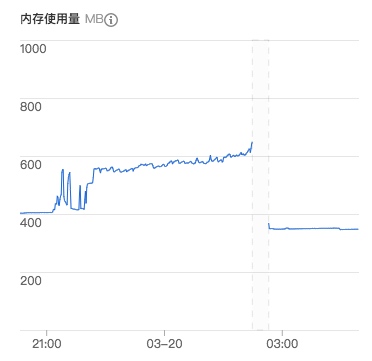
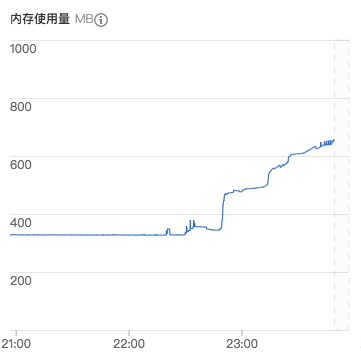
同时需要设置request队列的大小限制,因为爬取Github页面的时候可能爬取一个star列表以后就会产生几十个Request,这样很容易把Redis的队列挤爆:
1 | def enqueue_request(self, request): |
没有设置数量大小的时候,1G内存的主机跑一个多小时之后就挂掉了:
调度器
为了使用共同的请求队列,所以需要重写Scheduler,重写的Scheduler负责把要爬取的request放入队列以及从队列中找出request进行爬取
去重集合
本地爬虫通常需要解决一个去重问题,通常使用的是数据库查询,爬取之前判断url是否请求过。分布式爬虫就是在这个的基础上共用一个去重集合,使用的是Redis的set。
判断一个Request是否已经爬取过,这里不是使用url,因为不同的url可能代表的是同一种资源,比如:http://www.example.com/query?cat=222&id=111和http://www.example.com/query?cat=222&id=111 事实表示的是一个东西。此外,发出的Request还可能与当时的Cookie有关,因为里面还会有用户信息。
1 | # 计算Request指纹判断有没有重复 |
这里采用的方案是生成一个Request的指纹,实际上是把request的url,method和指定的header使用sha1算法得到一个hash值。
1 | # Request 指纹计算方法 |
反反爬虫策略
随机User-Agent
使用中间件实现随机User-Agent,随机替换掉request的header的User-Agent参数
1 |
|
Cookies池
首先使用多账号模拟登录,获取到很多已登录账号的cookies,放入到Redis的hashset中,各个爬虫共用这一个Cookies池。爬虫同样实现一个中间件,替换Request的Cookies。
1 | # Cookie 中间件 |
总结
这是一个为了了解分布式工作原理而做的一个小的项目,其中很多地方存在缺陷,欢迎大家在Github上留建议:
https://github.com/Sixzeroo/GithubCrawler
同时也可以查看下一篇关于Github用户和仓库数据分析的文章

