今天实验室的“周末算法讲堂”轮到我啦,今天主要讲的是匈牙利算法,主要用来解决最大的二分匹配问题(当然还可以用最大流来解决)。下面把握准备过程的资料整理总结出来吧。(感觉这么点东西讲的东西比较少,实验室的大佬们别介意啊)
后面会讲到在这个的基础上解决最大权完美匹配问题的KM算法
概念
二分图
如果图中点可以被分为两组,并且使得所有边都跨越组的边界,则这就是一个二分图。每一条边的两个端点都分别在两个组当中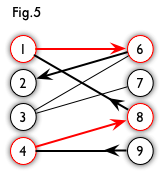
匹配
在图论中,一个「匹配」(matching)是原图边的一个子集,其中任意两条边都没有公共顶点。图中的点要么有一条边相连,要么没有边相连,不可能一个点和多条边相连。
最大匹配
一个图中含有匹配数最多的匹配
暴力算法
求出所有的匹配方案,从中选取覆盖顶点数最大的匹配方案。
最大流算法
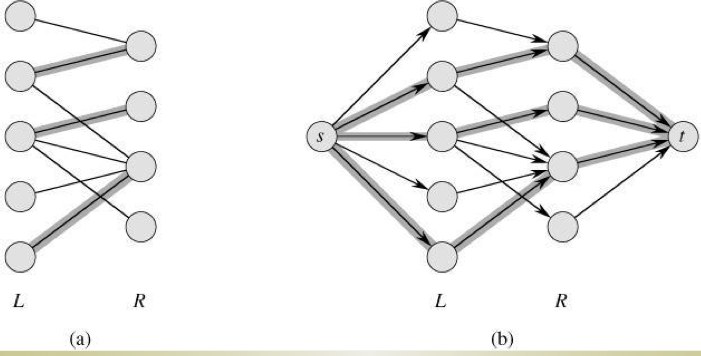
在两边各加一个源点和一个汇点,同时为两边的每一个点都添加一条指向源点/汇点的边,如图所示。同时从源点到汇点给每一条边都指定方向。这样问题就转换成最大流问题,通过最大流的相关算法就可以求解。
算法实现
匈牙利算法提供一种找图中的最大匹配的算法
增广路径
从未匹配点出发,交替通过未匹配边和已匹配边,最后到达另一个未匹配点的路径。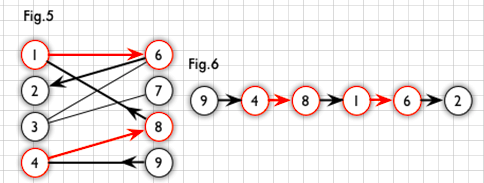
性质
- 增广路的长度一定是奇数,并且第一条边和最后一条边一定不是匹配边。
- 增广路径中未匹配边的数量始终比已匹配边的数量多一位。
这样通过反转(已匹配边变成未匹配边,未匹配边变成已匹配边)就可以增加一天匹配边。反转不改变匹配的性质。
可以证明,找到最大的匹配当且仅当找不到新的增广路:
最大匹配是一定不存在增广路,性质2容易证明
找不到增广路一定是最大匹配,证明比较麻烦,忽略
每找到一条增广路就可以增加一条匹配边。匈牙利算法实际上就是不断从未匹配点开始找增广路的算法。一个点找到匹配的边以后,以后寻找增广路的过程中这个点始终都会有匹配的边
算法流程
1、设置匹配为空
2、遍历每一个未匹配点,从这个点出发,找增广路。通常情况下我们只需要遍历一边的点就可以了,因为匹配边连接的两个点一定分别处在两个集合中,一边的点达到最大的匹配,另外一遍的点也必定会达到最大的匹配
3、记录匹配的边数,进行输出
复杂度分析
- 空间复杂度:空间复杂度主要来源于图的复杂度,使用链式前向星来存储图,空间复杂度为O(e)
- 时间复杂度:枚举一边的点的时间复杂度为O(v),在最坏的情况下每次寻找增广路的时间复杂度为O(e),所以总的时间复杂度为O(v*e)
实现模板
DFS实现1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54int matching[maxn],head[maxn];
bool visit[maxn];
int cnt,P,N;
struct Edge
{
int to;
int next;
};
Edge edge[maxn*maxn];
void Init()
{
cnt=0;
memset(head,-1,sizeof(head));
}
void add(int u,int v)
{
edge[cnt].to=v;
edge[cnt].next=head[u];
head[u]=cnt++;
}
bool dfs(int u)
{
for(int i=head[u];~i;i=edge[i].next)
{
int v=edge[i].to;
if(!visit[v])
{
visit[v]=1;
if(matching[v]==-1|| dfs(matching[v]))
{
matching[v]=u;
return true;
}
}
}
return false;
}
int huangay()
{
int ans=0;
memset(matching,-1,sizeof(matching));
for(int i=1;i<=P;i++)
{
memset(visit,0,sizeof(visit));
if(dfs(i)) ans++;
}
return ans;
}
POJ 1469
题意
给出N个学生和P堂课,以及每堂课报名的学生名单,存在以下对于课代表的规则:每个学生当一门课的课代表,每门课都有课代表。问是否存在满足上述条件的课代表组合。
题解
裸的匈牙利算法,只要将最后算法出来的匹配数和课堂树进行比对,相等的话就满足条件,否则不满足条件。
代码
1 |
|

