《深入理解计算机系统》第10章笔记
输入/输出(I/O)是在主存(memory)和外部设备之间拷贝数据的过程。输入数据是从I/O设备拷贝数据到主存,输出数据是从主存拷贝数据到I/O设备。
Unix I/O
所有的的I/O设备都模型化为文件,而所有的输入和输出都当作相应文件的读和写来执行。
所有的输入输出都以一种统一且一致的方式来执行:
- 打开文件
- 改变当前的文件位置
- 读写文件
- 关闭文件
打开和关闭文件
open函数将filename转换为一个文件描述符,并且返回描述符数字。返回的描述符总是在进程中当前没有打开的最小描述符
读和写文件

read函数从描述符为fd的当前文件位置拷贝至多n个字节到存储器位置buf。
write 函数从存储器位置拷贝至多n个字节到描述符fd的当前文件位置
通过调用lseek函数,应用程序能够显式地修改当前文件的位置
共享文件
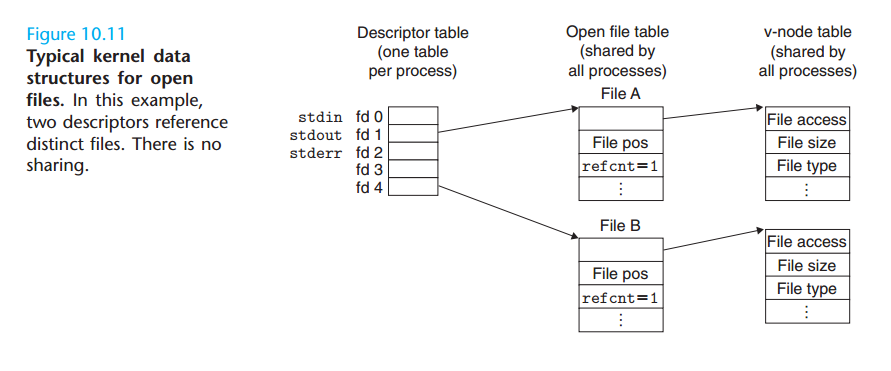
可以用许多不同的方式来共享 Unix 文件。内核用三个相关的数据结构来表示打开的文件:
- 描述符表(descriptor table)。每个进程都有它独立的描述符表,它的表项是由进程打开的文件描述符来索引的。每个打开的描述符表指向文件表中的一个表项。
- 文件表(file table)。打开文件的集合是由一张文件表来表示的,所有的进程共享这张表。每个文件表的表项包括当前的文件位置、引用计数(reference count),以及一个指向 v-node 表中对应表项的指针。
- v-node 表(v-node table)。同文件表一样,所有的进程共享这张表。每个表项包含 stat 结构中的大多数信息。
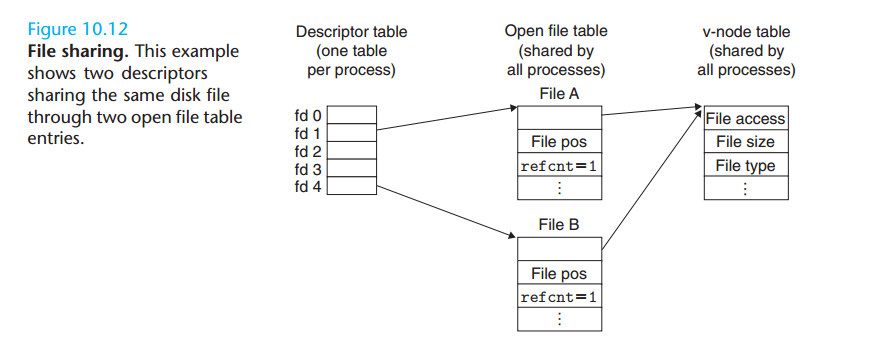
多个描述符也可以通过不同的文件表表项来引用同一个文件
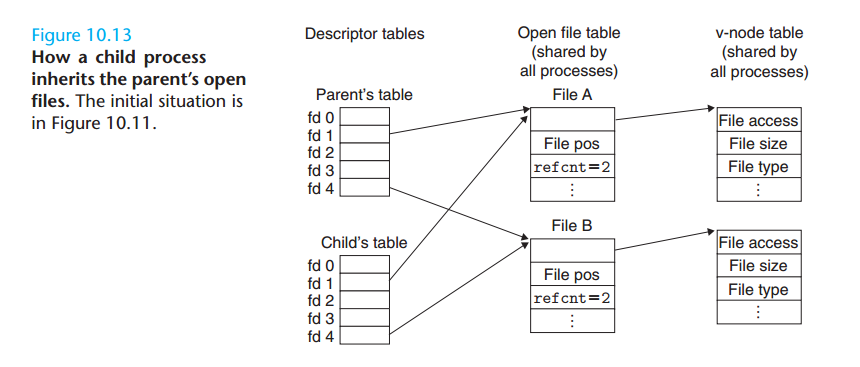
子进程继承父进程打开文件
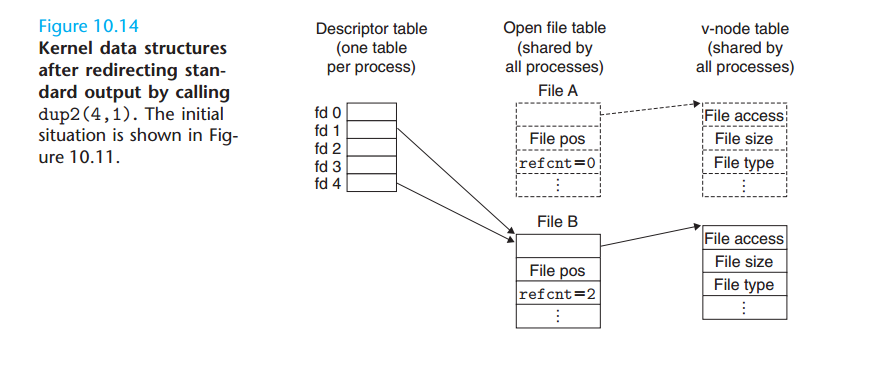
I/O重定向
我们该使用哪些I/O函数
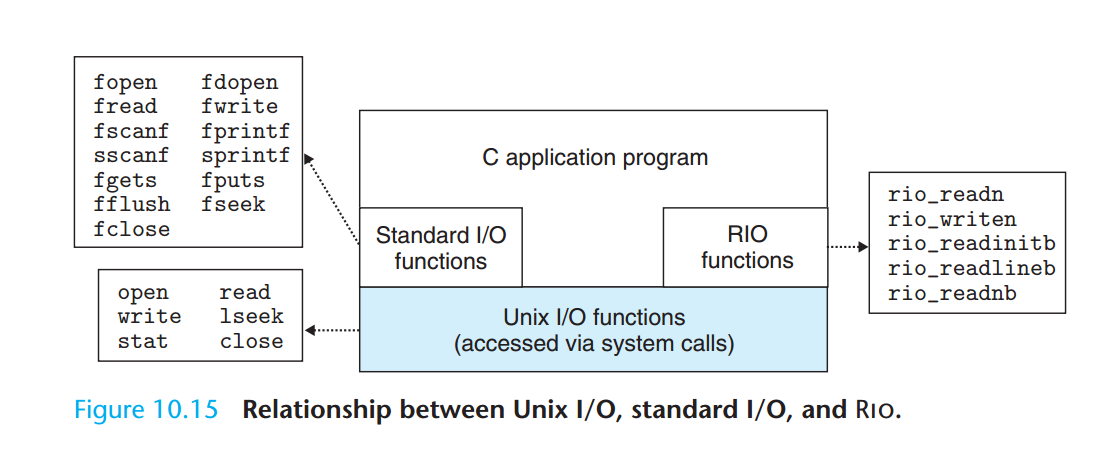
小结
Unix 提供了少量的系统级函数,它们允许应用程序打开、关闭、读和写文件,提取文件的元数据,以及执行 I/O 重定向。 Unix 的读和写操作会出现不足值,应用程序必须能正确地预计和处理这种情况。应用程序不应直接调用 Unix I/O 函数,而应该使用 RIO 包,RIO 包通过反复执行读写操作,直到传送完所有的请求数据,自动处理不足值。
Unix 内核使用三个相关的数据结构来表示打开的文件。描述符表中的表项指向打开文件表中的表项,而打开文件表中的表项又指向 v-node 表中的表项。
标准 I/O 库是基于 Unix I/O 实现的,并提供了一组强大的高级 I/O 例程。对于大多数应用程序而言,标准 I/O 更简单,是优于 Unix I/O 的选择。然而,因为对标准 I/O 和网络文件的一些相互不兼容的限制,Unix I/O 比标准 I/O 更适用于网络应用程序。

