Redis使用跳跃表作为有序集合键的底层实现之一,跳跃表(skiplist)是一种有序数据结构,它通过在每个节点中维持多个指向其他节点的指针,从而达到快速访问节点的目的。
跳跃表支持平均O(logN)、最坏O(N)复杂度的节点查找,还可以通过顺序性操作来批量处理节点。在大部分情况下,跳跃表的效率可以和平衡树相媲美,并且因为跳跃表的实现比平衡树要来得更为简单,所以有不少程序都使用跳跃表来代替平衡树。
数据结构
一个跳跃表的整体结构如下: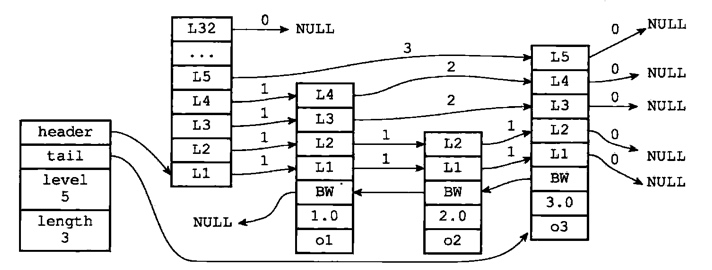
跳跃表节点
跳跃表节点的数据结构定义如下:1
2
3
4
5
6
7
8
9
10
11// 跳跃表节点
typedef struct zskiplistNode {
robj *obj; // 保存的值
double score; // 节点分值
struct zskiplistNode *backward; // 后退指针
// 层
struct zskiplistLevel {
struct zskiplistNode *forward; // 前进指针
unsigned int span; // 跨度
} level[];
} zskiplistNode;
- 层:level数组包含多个元素,每个元素都包含一个指向其他节点的指针,程序可以通过这些层来加快访问其他节点的速度,一般来说,层的数量越多,访问其他节点的速度就越快
- 前进指针:每个层都有一个指向表尾方向的前进指针,用于从表头向表尾方向访问节点
- 跨度:表示两个节点之间的距离(前进指针指向节点和当前节点的距离)
- 后退指针:用于从表尾向表头访问节点
- score分值:跳跃表中所有的节点按照分值进行排序
- obj:保存的成员,一般为sds数据结构
跳跃表
1 | // 跳跃表 |
跳跃表记录了头结点和尾结点的指针、长度(即跳跃表中节点数目)和层数最大的节点的层数,注意表头节点的层高并不计算在内。
基本操作
创建跳跃表
1 | // 创建跳跃表节点 |
可见:
- 创建的跳跃表的初识level层数值为1
- 刚创建的跳跃表的头结点是一个有32层的空节点,其中每一层的forward都是NULL
跳跃表插入节点
跳跃表插入节点的部分有些复杂,需要改变节点前后节点的forward、backward指针以及长度等信息。其基本思想是:使用update表记录新节点在各层中forward指针指向它的节点,然后插入,同时改变这些复杂的指向关系。
其中rank数组是用来记录每一个节点再整个节点表中的排位信息,其是通过每层中的跨度计算得来的。
新插入的节点的层数是通过幂次定律决定的一个1-32的数。
1 | // 返回一个1-32的层数值,使用幂次定律,越大的数出现的概率越小 |
跳跃表删除节点
删除节点的方法差不多就是插入节点方法的反向操作,首先找到目标节点(通过update数组记录沿途节点),接触forward指针关系,更新跳跃表的层数和长度
1 | /* Internal function used by zslDelete, zslDeleteByScore and zslDeleteByRank */ |
跳跃表查找节点
跳跃表中查找节点相关的操作主要有获取排名、依据排名获取信息。其基本思想和插入节点找到插入位置一样。
1 | // 通过分值和对象值获取排位信息,以1为起始值 |
用一张图能够简单表示这种查找行为,例如找到5这个节点: